Next-Generation Matching Engine: A Message-Driven Parallel Matching Engine
Centralized exchanges rely on a CLOB, or central limit order book, for matching. The matching rules are simple: price priority first, time priority second. For an exchange, the matching engine is foundational infrastructure. It must be stable, efficient, scalable, and fault-tolerant, and it must be able to recover or roll back quickly during extreme market conditions or system failures.
Message-Driven Parallel Matching
This article proposes a message-driven parallel matching engine. “Message-driven” means the matching engine accepts only one kind of input: a message queue such as Kafka. The second part is the key question: what exactly is parallel matching?
Parallel matching means multiple machines match orders at the same time. It is not a single primary with N replicas, and it is not round-robin scheduling. It is true simultaneous matching. The obvious concern is whether this causes state inconsistency. The answer is that the persistence layer, including Redis and the database, must be idempotent. In other words, even if the same order, identified by the same message ID, is processed many times by different matching engines, the persisted state should change only once.
There are two essential ingredients for parallel matching:
- A state machine
- Idempotence
State Machine
The core idea of parallel matching is to treat the matching engine as a state machine. The input is a Kafka message, and the output is the next state. The next state depends on both the previous state and the input message. In mathematical form:
For a matching engine, once the initial data has been loaded, the matching process no longer depends on environment variables or random inputs. Processing the same data yields a fully deterministic result. So in theory, the same initial conditions plus the same input must always produce the same output. That is the foundation of parallel matching.
This means we do not need the traditional approach of synchronizing multiple matching engines through multicast or similar replication protocols. Instead, we rely on the same initial state, the same input stream, the same processing pipeline, and periodic verification to guarantee that all matching engines stay consistent at the same message boundary.
That addresses in-memory consistency between matching engines, but it is only one piece of the system. Every layer still needs to be correct and fault-tolerant.
Idempotence
The mathematical form of idempotence is:
| |
That means applying the same input repeatedly always leads to the same final result.
For persistent storage such as Redis and databases, we rely on Kafka sequence id to guarantee idempotence.
First, every change in an order’s lifecycle is triggered by a Kafka message. Order creation is triggered by a user sending a buy or sell request. Matching is triggered by the arrival of a new order. Order completion is the result of matching, and therefore is also driven by new messages.
Second, changes to user balances can also be modeled as message-driven events. Typical balance changes come from:
- deposits
- withdrawals
- OTC activity
- all trading activity
At a larger scale, not only orders and balances but effectively every input to the system can be abstracted as a message. Then every state transition in the whole system becomes message-driven. Once the persistence layer is made idempotent, the entire system can be built on top of that model.
The real questions then become: how do we implement it, how do we guarantee correctness, how do we guarantee consistency, and how do we make it fault-tolerant?
Using sequence id as the Unit of State Synchronization
First, the architecture diagram:
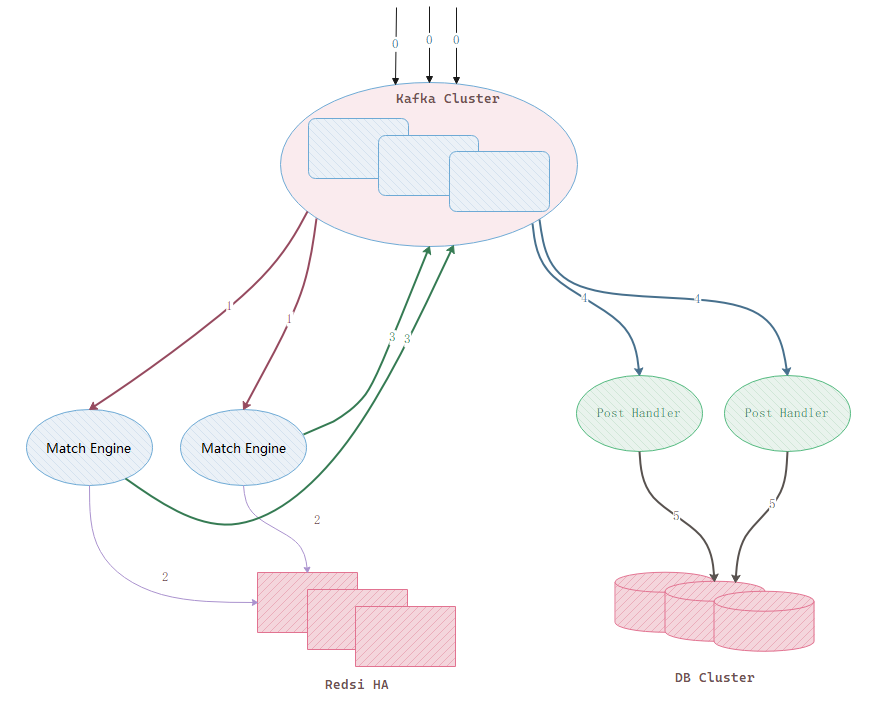
The message flow corresponding to the diagram is:
- Messages enter the Kafka queue.
- Each matching engine reads from Kafka and performs matching independently.
- Each matching engine writes its matching result into Redis HA, where message IDs enforce idempotence.
- After a matching engine successfully writes to Redis, it sends the downstream changes back to Kafka.
- Other modules consume the messages from step 3 and write them into the database with some delay.
Kafka is the core unit in this design. Every Kafka message has a sequence id, a 64-bit monotonically increasing positive integer. That sequence id is the ruler we use to measure system state. We rely on it to guarantee consistency across layers.
Concretely, order data is stored in three places:
- the matching engine’s memory
- Redis
- the database
What we need to guarantee is that for any given sequence ID, all three places reflect the same order state.
How to Guarantee Consistency Between Matching Engines
In theory, if every matching engine starts from the same initial data, consumes the same messages, and processes them in the same order, then the in-memory orderbook at a given message boundary should be identical across all engines.
Of course, that is only the theory. To verify it in practice, we can design a special Kafka message type. When a matching engine receives this message, it computes a hash of its in-memory orderbook and publishes the result back to Kafka. Each matching engine then reads the hashes from its peers and compares them with its own.
If the hashes are identical, the state is consistent. If they differ, the engines can continue drilling down by hashing individual price levels until they locate the exact point of divergence. At that point, an engineer can investigate why the inconsistency occurred.
This verification can run very frequently, for example once every 10 seconds. That makes it much easier to pinpoint issues quickly while the relevant data is still fresh.
Verification is only half of the story. What happens after an inconsistency is detected? Suppose we have identified the source of truth and want to use one engine’s state as the baseline. In that case, we can define a synchronization message that instructs the healthy matching engine to publish its full order book to Kafka, and the other engines can overwrite their local order books with that data. The process is basically the same as bootstrapping from a snapshot during startup.
How Other Matching Engines Synchronize on Startup
Because the data exists in three places, a matching engine can bootstrap from three possible sources:
- the memory of another matching engine
- Redis
- the database
The best source is another matching engine, because that is the freshest data and usually the most internally consistent.
Reading from Redis or the database is more complicated, especially in clustered deployments, because the storage layout matters. For example, if an order book for a trading pair is sharded across multiple Redis cluster nodes, it becomes difficult to guarantee that data read from different machines corresponds to the same sequence id.
Synchronizing from another matching engine can work like this:
- Send a synchronization request message to Kafka.
- A healthy matching engine responds by publishing the order book to Kafka.
- The recovering engine reads the order-book snapshot, obtains both the book and the corresponding
sequence id, initializes its local state, and then resumes consuming Kafka from that exact sequence boundary.
What if the primary matching engine fails during this process? If no matching engine is processing messages at that moment, then both the Redis cluster and the database cluster are frozen at the state of the last processed Kafka message. Because database replication usually lags Redis, Redis becomes the preferred recovery source. Since state is no longer changing, every Redis node should correspond to the same Kafka message ID, so we can simply read the data from Redis and reconstruct the order book.
Fault Tolerance
Because multiple machines are matching at the same time, this design is naturally fault-tolerant. The key requirement is simply to guarantee that all matching engines hold consistent in-memory state at the same message boundary.
Periodic Validation
Kafka can be used to broadcast a check instruction message. When a matching engine receives it, it computes a hash of the order books for the trading pairs it manages and publishes the result for comparison. The hash values across all matching engines must be identical. If they are not, the discrepancy needs to be investigated immediately.
Optimization
Under the design above, the number of messages sent back into Kafka grows significantly, which in turn increases downstream processing load. How should this architecture be optimized? Based on the analysis above, we know where the overhead comes from, and that becomes the starting point for the next step of design.
Implementation Details
There are still many implementation details worth discussing later, such as:
- the data structures used for matching
- the storage format in Redis
- Redis transaction design
- and other persistence-layer details
Advantages
Loose Coupling Between Matching Engines
Continuous Consistency Across Matching Engines
Easy to Upgrade and Easy to Test
Real-Time Verification and Monitoring
Drawbacks
The message volume increases by roughly 1/N or more depending on the exact architecture. In one design it grows by N times, while in another it only grows by about one additional copy.
The number of Redis writes also increases by N times.